Automating blogging workflow - Part One
Mar 9, 2022 13:31 · 881 words · 5 minute read
Introduction
This post will be the first in a series of posts about the management of my site, and the why and how I’ve improved the management of the site.
This is mostly to show how automation can be applied to many use-cases, but also how I now see most workflows as an opportunity to be automated. What better way to prove it than automating the very words you are reading!
Background
I started this blog in 2019, and at that point in time, I decided to build and host my Hugo static site in Amazon Web Services (AWS). Whilst it may have been easier to use something like Wordpress, I wanted to take the opportunity to learn more about AWS and other technologies. Combining learning with an immediate need is one of the best ways of learning in my view.
The website was built mainly using ‘ClickOps’, which allowed me to understand the concepts and see how resources are associated together.
Current Workflow
Up until recently, the high level workflow was as is shown below:
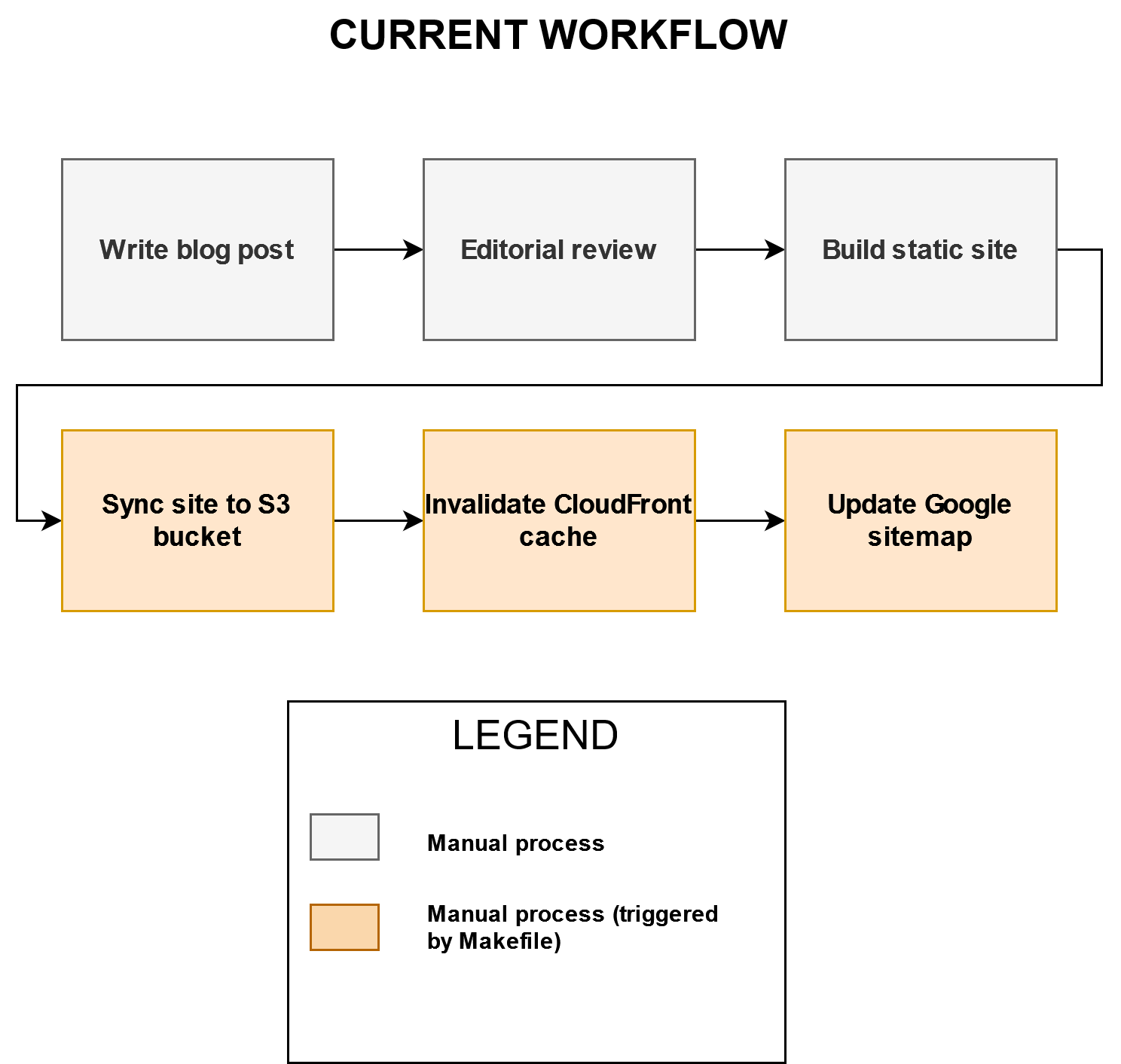
Each step is described in more detailed below.
Write blog post
This would involve writing a blog post in Markdown format. As you can guess, this is a manual process which can’t be improved other than more practice.
Editorial review
After writing the post, I would perform an editorial review to review for:
- Spelling and grammar issues
- Flow or sequencing of the blog post content
- Removal of repetition or unclear information
This is all done manually, or using spell check tools using plugins in my integrated development environment (IDE).
Build static site
Once it had passed any editorial checks, it was time to build the Hugo static site, which generates and prepare the static site to be hosted.
Sync site to S3 bucket
After the site is ready, I would synchronise the Hugo static site files to the Amazon Simple Storage Service (S3) bucket, which will serve the files for my site. The synchronisation was performed using the AWS Command Line Interface (CLI) from my local machine.
Invalidate CloudFront cache
Once the files are successfully synchronised, the next step was to invalidate the CloudFront cache after the new blog post is published, to ensure that the latest content is available using the AWS CLI. In this case, this would be the new blog post.
Update Google sitemap
Finally, I also notify Google that a new copy of my site map is available to crawl so it can efficiently indexed and searched.
What’s not shown in this workflow is that my site’s blog post and configuration data is also stored on GitHub, to make version control and administration of the site more reliable.
Limitations
There were a few limitations with this current approach, which are listed out below:
- In the editorial review process, I would invariably miss spelling or grammar mistakes. This would happen out of either out of repeatedly reading the same thing and losing concentration, or just the sheer content involved in some of the bigger blog posts. In other words, I’m a human, doing human things :)
- Using the AWS CLI requires you to keep a local copy of an AWS Access Key ID and Secret Access Key. I change between machines for deployment, so having to constantly copy these values around is more friction. In one instance, my machine had an onboard wireless adapter malfunction, which meant I had to re-image my machine and buy an external USB wireless adapter. I like all my tooling where possible to not be reliant on a single machine.
- In a haze of attempting to learn AWS, I had fallen into the lazy trap of using a powerful IAM user to administer my website. It was effectively an AWS admin account, which doesn’t follow the best practice of least privilege access.
- I can deploy the site from any branch, and possibly not even commit those changes to GitHub. This would result in the site being out of sync with Git if I deployed the site without committing.
Goals for improvement
After thinking about some of the current limitations, coupled with my experience in Azure Pipelines and GitHub Actions, I decided on the following goals to improve the management of my site:
- Automate spelling, grammar and writing style checks, to uplift quality and speed of those checks.
- Remove all reliance on a local machine for deployment, which includes removing the storage of AWS access credentials.
- Issue a new set of AWS access credentials, which have as least access as is possible to perform those tasks.
- Integrate Git as a mandatory method for deployment and approvals to update the site.
- Automate as much of the workflow as possible, using a hosted CI/CD tool.
Ultimately, my vision was to manage my blog in a CI/CD pipeline, much like the way I’ve come to administer other workflows in the last three years.
Approach
I decided that the best approach was to improve the current workflow in two iterations, so that there weren’t too many moving parts and unknowns to contend with.
Conclusion
In this post, I covered the current workflow to administer my site, it’s limitations and what are the goals for improvement. In the next blog post, I will cover the first iteration of improvement.
Thank you for reading